【Bubble】正規表現をマスターして開発の幅を広げよう
正規表現とは
正規表現は、文字列の検索や置換などをするために使用されます。
正規表現を使用すると、文字列内に特定のパターンが含まれているかどうかを確認したり、文字列中の一部を置き換えできます。
ユースケース
- コンマで区切られたテキスト文字列をテキストリストに変換する
- URLからパラメータ値を抽出する
- ファイル名の拡張子を抽出する
Bubbleで正規表現を使うには
Bubbleで正規表現を用いるために使われる演算子として、「:extract with regex」「:find & replace」演算子があります。
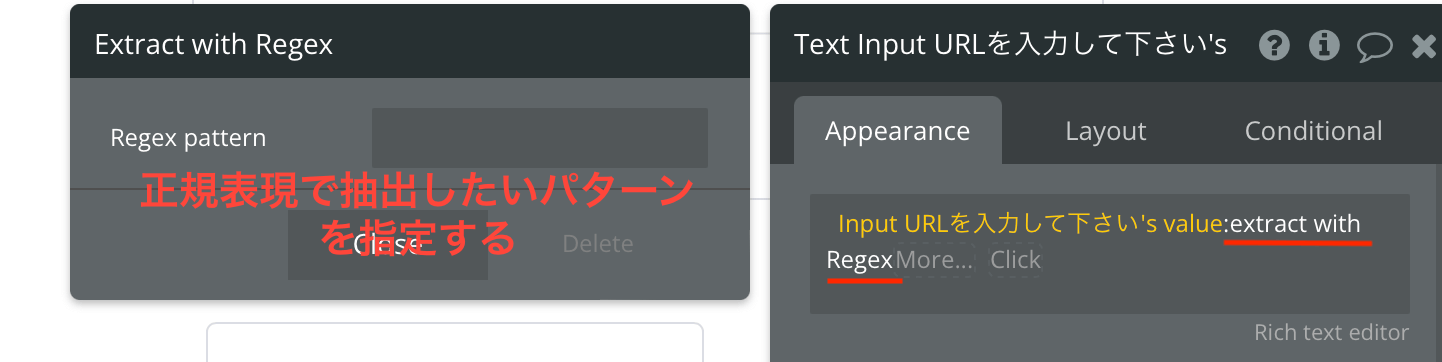
- :extract with regex
- この演算子は、入力された文字列から一部だけを抽出したいときに使用します。抜き出したいパターンを正規表現で指定します。
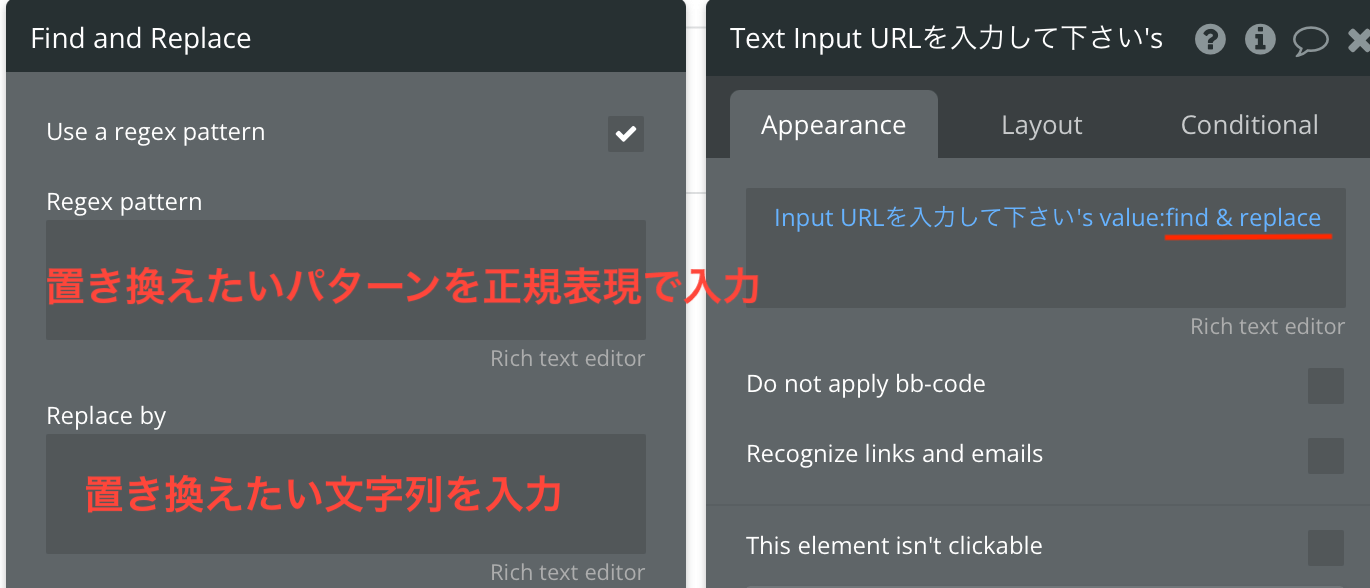
- :find & replace
- あるパターンを指定の単語や文字列で置き換えたいときに使用します。
ハンズオン-URLからデータの抽出
それでは、実際の例で正規表現を用いて、データの抽出を行なっていきます。
今回は、正規表現を使って、URLからドメイン部分だけを抽出します。
まず入力欄とテキストボックスを作成します。
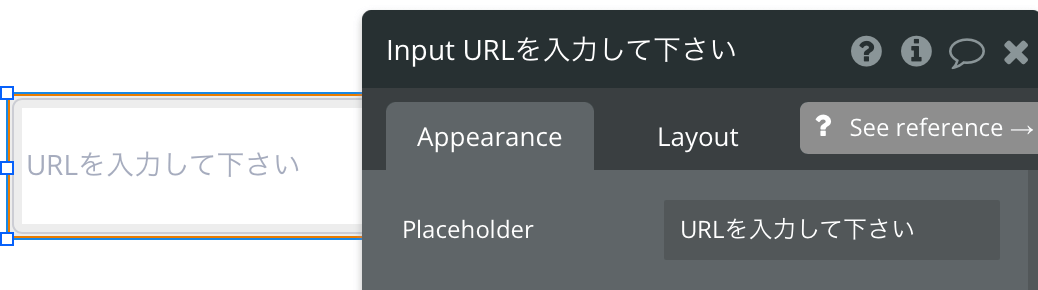
今回の例は、データの抽出をしたいので「:extract with regex」を用います。
ドメイン部分を抽出するために、Regex patternを「^https?://[^/]+/」に設定します。
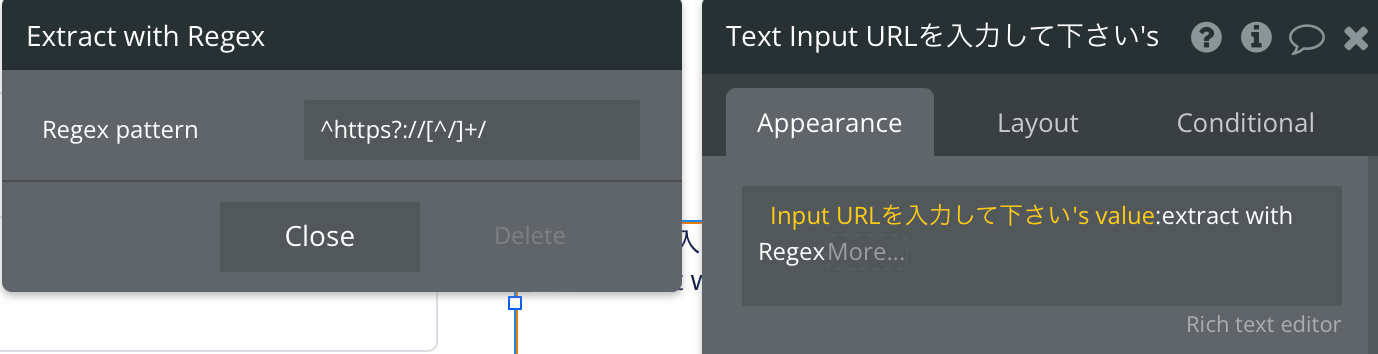
URLのドメイン部分のみが、テキスト部分に抽出できていることが分かります。

便利な正規表現まとめ
最後に便利な正規表現をまとめておきます。
| メタキャラクタ | 意味 |
|---|---|
| ・ | 任意の一文字 |
| \w | 英単語を構成する文字(a~z,A~Z,_,1~9) |
| \W | 英単語を構成する文字以外 |
| \s | 空白文字(半角スペース,タブ,改行,キャリッジリターン) |
| \S | 空白文字以外 |
| \d | 半角数字(0~9) |
| \D | 半角数字以外 |
| \d | 単語の境界に一致 |
| [xyz] | 指定された文字のどれかに一致(この場合xyzのいずれかに一致) |
| [a-z] | マッチする文字の範囲を指定(この場合aからzまでのいずれかに一致) |
| (pattern1|pattern2) | 指定されたパターンのどれかにマッチする表現 |
| ? | 直前の文字が全くない、もしくは一つだけある |
| () | カッコ内の文字列をグループ化する |
| \n | 改行文字 |
| \s | 空白文字(スペース・タブ文字・改行・改ページ) |
| \S | 非空白文字 |
| $ | 行の終わり |
| ^ | 行の先頭 |
| * | 直前の文字がない、もしくは直前の文字が一個以上連続する |
| + | 直前の文字が最低一個以上ある |
| | | 区切られた文字列のいずれかの文字列が存在する |